AtCoder Beginner Contest 232 セルフ反省会
3ヶ月ぶりのコンテスト。
色々となまってた部分もあった。
A. QQ solver
自分ライブラリありのテンプレートファイルの使い方を忘れて焦った。
なまってた部分。
B. Caser Cipher
カエサル暗号のやつ。
実装ミスってWAを出してしまう。
単純にmodの世界の話だった。
けど、mod26実装でエラーを出してしまい、その後変なことをしすぎた。
B問題なんだから、mod26でしょ、というところ勘所が、完全になまってた。
C. Graph Isomorphism
問題文の読解不足だった。
はじめは、
N, M = mulinputs()
inabs = []
for _ in range(M):
A, B = mulinputs()
inabs.append((A,B))
incds = []
for _ in range(M):
C, D = mulinputs()
incds.append((C,D))
l = list(range(N))
is_hit = True
for p in permutations(l, N):
for i in range(N):
a, b = inabs[i]
c, d = incds[p[i]]
if a != c or b != d:
is_hit = False
break
if is_hit:
print('Yes')
exit()
print('No')
でうまく行かなかった。
「グラフの同型問題では?」と思い立ち、グラフの同型チェックのアルゴリズムを実装しようとして時間切れ。
実は、問題文を誤解していて、はじめの実装だと、
「紐の並び替え」
問題への解答になってしまっている。
「紐が結びつくボールが、AB-CDで同じ」という考え方になってしまっている。
これだと、例題1の
A-B <=> C-D 1-2 2-3 1-3 1-4 1-4 2-3 3-4 3-4
に対応できない。
問題の中心は「ボールの並び替え」なので、そもそも問題文をよく理解してなかった。
解答の
n, m = map(int, input().split()) a = [[False] * n for _ in range(n)] b = [[False] * n for _ in range(n)] for _ in range(m): u, v = map(int, input().split()) u -= 1 v -= 1 a[u][v] = a[v][u] = True for _ in range(m): u, v = map(int, input().split()) u -= 1 v -= 1 b[u][v] = b[v][u] = True
この部分で、ボールのつながりに関するマトリクス(隣接行列?)を作ってる。
このマトリクスの行/列を並び替えて、一致するかを見る=「ボールの繋がり方」が一致するか見る、という問題だった。
D. Weak Takahashi
未だに何でWAが出たのかわからない。
自分は、下から上のボトムアップな解答方法で、 模範解答は、上から下のトップダウンな解答方法、
という違いしか認識できてない。
たぶん、境界値とか変なデータの形状を認識できていないのだと思う。
結果を突合してみないともうわからないと思う。
テストデータとか公開してくれないだろうか…
(古いのはあるけど、最近のって公開されていないイメージ)
追記 (2021/12/19 23:54)
他の人の提出結果を見て、実装の悪いところがわかった。
幅優先探索で、枝切りしてたところが間違い。
while not q.empty():
x, y = q.get
# (i, j+1)
if y + 1 < W and maize[x][y + 1] == '.':
hosuu[x][y+1] = hosuu[x][y] + 1
q.put((x, y + 1))
continue
# (i+1, j)
if x + 1 < H and maize[x + 1][y] == '.':
hosuu[x+1][y] = hosuu[x][y] + 1
q.put((x + 1, y))
continue
「マス (i,j+1) またはマス (i+1,j)」と言ってるので、上記でcontinueするのは間違い
(「または」というところがおかしいだろうとは思ってたけど、枝切りに気づけなかった。恥ずかしい……。)
continueをすると、今度はTLEで通らなかった。
どうやら、
- queue.Queueは(くっそ)重い
- おんなじところをぐるぐる探索していた
様子。
queue.Queueは重いので、collections.dequeuを使うのがいいみたい。
あと、メモリ使いすぎなところから、同じところを探索していることに気づけた。
(i, j+1)→(i+1, j)と(i+1, j)→(i, j+1)は同じところを見に行く。 単純に考えると、探索範囲が2倍ぐらいになるので、ピーキーなデータだと間に合わなくなる。
いつも、「実行時間」しか見てなかったけど「メモリ」も有益な情報だって、気づけたことが大きい。
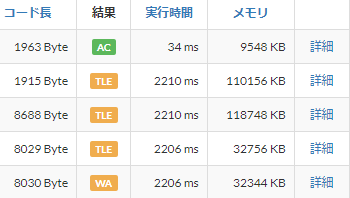
これで、どうにかD問題を解決することができた。
これで、QOLがちょっぴり上がった