Ubuntuを入れているPCのストレージを交換してディスクを増強する
目的
Ubuntu20.04LTSのサポートが切れるので、24.04LTSにアップデートしたい。
その前に、ディスクがカツカツなので、拡張する。
前提
やったこと
まずは、ネットの情報を見て物理的にディスクを交換する([*1]{#1})。
このとき電源を落とすだけでなく、BIOS設定で、バッテリーを無効化する。
起動画面でF1連打。その後、[Config] > [Power] > [Disable build-in buttery] と進む。
「今すぐ電源落とすけどいい?」と訊かれるので[YES]と応える。
「電源落とすけど、電源ケーブルにつなげたら、自動でこの項目はEnableになります」と書いてあるので、再起動後のBIOS変更はいらない模様。 (メッセージを読まないで電源落としたので、作業完了後の再起動時に気づいた…)
底板は、精密ドライバーとこじ開け器であけた。
LANケーブルの口がある側のUSBポート付近が強固に密着して開かなかった。 この部分だけは、大部分の基盤とは独立した基盤になっている。 ちゃんと見ていなかったが、基盤が二重になっているのか、コの字型のスリットが入っている気がする。 これによって、LANケーブル口側真ん中のネジが固着して、うまく離れなかった。 ドライバーで何度もネジを回してたらそのうち取れるようになった。
あと、底板を開ける/締めるときに、バッテリー側の爪を2つダメにしてしまった。 折れやすいので注意。めっちゃ、注意。
SSDのクローンは、玄人志向の物理的にディスクをクローンする器械(*2)を使った。
500GB→1TBのディスクへのクローンだが、40〜50分ぐらいかかった。
クローン完了後、1TBのディスクをマシンに接続する。
SSD固定していたネジを紛失してしまった…。
PCを起動して、【システムモニター】でディスク容量を確認する。
500GBのまま、だと…?!
【ディスク】で確認してみると、どうも増えた分の500GBぐらいが「未割り当て」となっている。
【ディスク】で現在のパーティションを選択肢、「サイズを変更する」で最大サイズに設定してもエラーとなってしまう。 (エラーメッセージは忘れた)
どうもパーティションとかの設定をしないといけないっぽい?
ここの記事(*3)を参考に、コマンドを投入する。
$ sudo parted (parted) print free (parted) resizepart 2 (parted) quit $ sudo resize2fs /dev/sda2
(resize2fsとか、LinuC Lv1でみた気がする…)
これで無事ディスクを1TBにすることができた。
*1: ThinkPad X260のハードディスクとメモリの交換 | ひがし研究所
[*3]{#3}: UbuntuサーバのHDDを交換して容量を増やす手順とは - Seshat - Windows, Linux, macOS -
pandocの使い方
使うたびに「オプションなんだっけ?」ってなるのがめんどくさいので、まとめておく。
# USAGE pandoc -f INPUT-FORMAT -t OUTPUT-FORMAT -o OUT-FILENAME -c style.css source_file.md --self-contained # example pandoc -f markdown -t html -o index.html entry.md --self-contained
--self-containedオプションで、リソースまとめた一つのHTMLファイルに出力してくれる。
例えば、画像をつけたmdだったら、Base64に変換した画像を含むHTMLにしてくれる。
cssを外から変えたい場合は-cオプションを使う。
これで、ちょっぴりとQOLが上がった。
最短経路アルゴリズムの理解:Dijkstra
最短経路のアルゴリズムにもいろいろある。
その中でもダイクストラのアルゴリズムについて、理解した内容をまとめてみる。
基本戦略
- いま注目してる頂点に隣接する頂点をみる
- 隣接頂点が持つコスト(初期値はINF)と、いま注目している頂点のコスト+隣接頂点までのコスト(更新コスト)とを比較する 2-1. 更新コストが、隣接頂点が持つコストより小さかったら、隣接頂点のコストを更新コストで更新する
- 全長頂点中、まだ最小値が確定していない頂点の内、最小のコストを持たない頂点を次の探査対象にして、1.にもどる
こんなところ。
ネットを調べればもっとまともな解説が落ちてます。 厳密orわかりやすいものを求める人は、検索してください。
入力について
以降、アルゴリズムの説明に入ります。
基本型と効率型を載せますが、どちらも入力は以下の様な感じ。
# |V| |E| s 5 7 0 # V_prev V_next Cost 1 2 7 1 3 4 1 4 3 2 3 1 2 5 2 3 5 6 4 5 5
基本型
if __name__ == '__main__': Vn, En, r = mulinputs() G = [None] * Vn for _ in range(En): vp, vn, cost = mulinputs() if not G[vp]: G[vp] = [] G[vp].append((vn, cost)) # INFで初期化 v_cost = [INF] * Vn # 開始頂点はコスト0 v_cost[r] = 0 # Queue.queueよりもcollections.dequeのほうが速いし安定してる q = deque() q.append(r) dones = [False] * Vn while q: current = q.popleft() if visited[current]: continue dones[current] = True for v, e in G[current] or []: if v_cost[current] + e >= v_cost[v]: continue v_cost[v] = v_cost[current] + e # (☆1)まだ最小コストが確定していない頂点の中から # コストが最小のものを選ぶ min_cost = INF next_v = -1 # 0はFalseと混同するので使わない for v in range(Vn): if dones[v]: continue if min_cost > v_cost[v]: min_cost = v_cost[v] next_v = v if next_v >= 0: q.append(next_v) # 結果を出力する for cost in v_cost: if cost < INF: print(cost) else: print('INF')
☆1:なぜ最小コストの頂点なのか
隣接頂点のコストを更新する際に、自身のコストを使用する。
このとき、自身の頂点のコストが最小でない場合、後続の処理でコストが更新される可能性がある。
更新されてしますと、更新した隣接頂点のコストも更新する必要があって効率が悪い。
(ほかにも、「最短経路」を求めるのに隣接頂点のコストが「最短」でなくなってしまう)
効率型
優先度付きキューを使う。
そうすると、基本型であった「すべての頂点からコストが最小のものを選ぶ」部分を省略できる。
「すべての頂点からコストが最小のものを選ぶ」部分は、線形なのでO(N)の時間計算量がかかっていた。
優先度付きキューを使うことで、この時間計算量がO(logN)に改善することができる。
(優先度付きキューは、ヒープで実装されているみたい)
また、優先度付きキューを使うと、ソースの見た目が基本型とがらっと変わる。
ミソは、(cost, vertex)の順番でキューにデータを突っ込んでいくこと。
heapqでヒープを作るとき、デフォルトで第0番目のデータを使うみたいだから。 (この場合はcost)
ここのJudgeでTLEを喰らって頑張って効率型を書いた。ドチャクソ速くなった。 (9.0秒→0.1秒ぐらい)
参考
Vn, En, r = mulinputs()
G = [None] * Vn
for _ in range(En):
v1, v2, cost = mulinputs()
if not G[v1]:
G[v1] = []
G[v1].append((cost, v2))
v_cost = [INF] * Vn
v_cost[r] = 0
# ヒープにするキュー(リスト)
# 最小コストで並べ替えたいから、(コスト, 頂点)の順に定義する
q = [(0, r)]
dones = [False] * Vn
while q:
cost, v1 = heapq.heappop(q)
if dones[v1]:
continue
dones[v1] = True
# 隣接する頂点更新だけで十分
# 優先度付きキューを使ってるから、
# 最小コストの頂点を見つけるためにループを回さなくていい
for c2, v2 in G[v1] or []:
before_cost = v_cost[v2]
after_cost = cost + c2
if before_cost > after_cost:
v_cost[v2] = after_cost
heapq.heappush(q, (before_cost, v2))
for cost in mins:
if cost < INF:
print(cost)
else:
print('INF')
AtCoder Beginner Contest 232 セルフ反省会
3ヶ月ぶりのコンテスト。
色々となまってた部分もあった。
A. QQ solver
自分ライブラリありのテンプレートファイルの使い方を忘れて焦った。
なまってた部分。
B. Caser Cipher
カエサル暗号のやつ。
実装ミスってWAを出してしまう。
単純にmodの世界の話だった。
けど、mod26実装でエラーを出してしまい、その後変なことをしすぎた。
B問題なんだから、mod26でしょ、というところ勘所が、完全になまってた。
C. Graph Isomorphism
問題文の読解不足だった。
はじめは、
N, M = mulinputs()
inabs = []
for _ in range(M):
A, B = mulinputs()
inabs.append((A,B))
incds = []
for _ in range(M):
C, D = mulinputs()
incds.append((C,D))
l = list(range(N))
is_hit = True
for p in permutations(l, N):
for i in range(N):
a, b = inabs[i]
c, d = incds[p[i]]
if a != c or b != d:
is_hit = False
break
if is_hit:
print('Yes')
exit()
print('No')
でうまく行かなかった。
「グラフの同型問題では?」と思い立ち、グラフの同型チェックのアルゴリズムを実装しようとして時間切れ。
実は、問題文を誤解していて、はじめの実装だと、
「紐の並び替え」
問題への解答になってしまっている。
「紐が結びつくボールが、AB-CDで同じ」という考え方になってしまっている。
これだと、例題1の
A-B <=> C-D 1-2 2-3 1-3 1-4 1-4 2-3 3-4 3-4
に対応できない。
問題の中心は「ボールの並び替え」なので、そもそも問題文をよく理解してなかった。
解答の
n, m = map(int, input().split()) a = [[False] * n for _ in range(n)] b = [[False] * n for _ in range(n)] for _ in range(m): u, v = map(int, input().split()) u -= 1 v -= 1 a[u][v] = a[v][u] = True for _ in range(m): u, v = map(int, input().split()) u -= 1 v -= 1 b[u][v] = b[v][u] = True
この部分で、ボールのつながりに関するマトリクス(隣接行列?)を作ってる。
このマトリクスの行/列を並び替えて、一致するかを見る=「ボールの繋がり方」が一致するか見る、という問題だった。
D. Weak Takahashi
未だに何でWAが出たのかわからない。
自分は、下から上のボトムアップな解答方法で、 模範解答は、上から下のトップダウンな解答方法、
という違いしか認識できてない。
たぶん、境界値とか変なデータの形状を認識できていないのだと思う。
結果を突合してみないともうわからないと思う。
テストデータとか公開してくれないだろうか…
(古いのはあるけど、最近のって公開されていないイメージ)
追記 (2021/12/19 23:54)
他の人の提出結果を見て、実装の悪いところがわかった。
幅優先探索で、枝切りしてたところが間違い。
while not q.empty():
x, y = q.get
# (i, j+1)
if y + 1 < W and maize[x][y + 1] == '.':
hosuu[x][y+1] = hosuu[x][y] + 1
q.put((x, y + 1))
continue
# (i+1, j)
if x + 1 < H and maize[x + 1][y] == '.':
hosuu[x+1][y] = hosuu[x][y] + 1
q.put((x + 1, y))
continue
「マス (i,j+1) またはマス (i+1,j)」と言ってるので、上記でcontinueするのは間違い
(「または」というところがおかしいだろうとは思ってたけど、枝切りに気づけなかった。恥ずかしい……。)
continueをすると、今度はTLEで通らなかった。
どうやら、
- queue.Queueは(くっそ)重い
- おんなじところをぐるぐる探索していた
様子。
queue.Queueは重いので、collections.dequeuを使うのがいいみたい。
あと、メモリ使いすぎなところから、同じところを探索していることに気づけた。
(i, j+1)→(i+1, j)と(i+1, j)→(i, j+1)は同じところを見に行く。 単純に考えると、探索範囲が2倍ぐらいになるので、ピーキーなデータだと間に合わなくなる。
いつも、「実行時間」しか見てなかったけど「メモリ」も有益な情報だって、気づけたことが大きい。
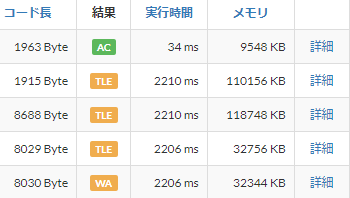
これで、どうにかD問題を解決することができた。
これで、QOLがちょっぴり上がった
gitの認証でたくさんのsshキーがありすぎるときの解決方法
僕の場合、リポジトリA、リポジトリBでそれぞれ異なるSSHキーを使っていることがある。
例えば会社絡みリポジロリではid_rsa_aで、個人プロジェクトではid_rsa_b、推し事関連ではid_rsa_cなど。
git push するとき、それぞれで合う秘密鍵を指定してgit pushしてる。
まあだけど、いつもググってばっかりなので、備忘を残す。
運用を見直せってのもあると思うけど、ちょっと思いつかない。
TL;DR
~/.ssh/configに設定を追加する- git の remote 設定を変更する
詳しくはここ
configファイルを作成する
~/.ssh/にconfigファイルを作成する。
以下の要領でconfigファイルを設定する。
Host hogehoge
HostName github.com # このホスト設定で使いたいGitのホスティングサービス
IdentityFile ~/.ssh/id_rsa_hoge # 秘密鍵の方
User git # githubとかでクローンするとき`git@github.com`ってなってると思うけど、その`@`の前のやつ
IdentitiesOnly yes
Compression yes
Host fuga
HostName github.com
IdentityFile ~/.ssh/id_rsa_fuga
User git
IdentitiesOnly yes
Compression yes
remoteの設定を変更する
git remote -vで
origin git@github.com:hogehoge/fuga-project.git (fetch) origin git@github.com:hogehoge/fuga-project.git (push)
とか出てくる。
このURL git@github.com:piyo/fuga-project.git を、configファイルで設定したものに書き換える
git remote set-url origin hoge:piyo/fuga-project.git
上記のコマンドで、
origin hoge:hogehoge/fuga-project.git (fetch) origin hoge:hogehoge/fuga-project.git (push)
となる。
これで、git push時に、configで設定した秘密鍵が勝手に当たるようになる。
QOLがちょっぴり上がった。
SurfaceのWindows10を初期化に失敗したメモ
学生時代から使っているSurface3の調子が良くないので初期化することにした。
学生時代に調達したPC。気づけばもう10年選手だった。
CrystalDiskinfoによると、SSDはまだ大丈夫っぽい。一般的な対応年数2倍超化してるけど。
TL;DR
- 32GBのUSBを調達して、回復ドライブを作成する
- Surfaceでは回復環境に入るために「音量キー下」長押しで電源投入
- 画面に書いてある回復キーはトラップ。MSアカウントで回復キーを発行したものを入力(別PCとMSアカウントが必須)
回復ドライブの作成
どこかにある「回復」ボタンを押せば、初期化できると思ってました。
これは、「Windows10は回復用のディスクイメージを、ハードディスク内にこっそり持っている」という認識だったからです。
確かに、Windows10では、Cドライブとは別に「システムで予約済み」のパーティションができます。
ここに初期化に必要な最小限のプログラムが収まってると思ってましたが、実際にはWindows回復環境(Windows RE)が収まってるみたいです。
結論を言うと、回復ドライブが必要です。
まあ、リカバリメディアみたいなものですかね?
ここの記事を参考にして、おとなしく回復ドライブを作成します。
32GBのUSBですが、近所のヤマダ電機でBuffeloのものを880円ぐらいで調達してきました。
あとはSurfaceにぶっ刺して、
コントロールパネル > システムとセキュリティ > セキュリティとメンテナンス > 回復
まで来たら、あとは画面の指示に従うってポチポチしていくだけでした。
SurfaceのBIOS
大体はPC起動時にF12かF11かF8を連打してれば入れる画面です。
Surfaceでも同様だと思って、F12やF11やF8を連打しました。
入れませんでした。
「音量キー上」長押し + 「電源ボタン」
だそうです。
特殊です。
しかも、回復ドライブから初期化する場合はWindows回復環境を立ち上げるみたいです。
これは、
「音量キー下」長押し + 「電源ボタン」
です。
これは知らないとハマりますね……
MSアカウントから回復キーを取得する
一番のトラップです。
回復ドライブから回復を選ぶと、回復キーの入力を求められます。
画面に回復キーが出てるので、それを入力しようとすると、アルファベットの入力が反応しない……
調べてみると、同じ画面に表示されているURLにアクセスし、MSアカウントでログイン後、回復キーが手に入る仕様みたいです。
別PCを持ってなかったり、MSアカウント持ってなかったらアウトです。
最後に
ここまで書いておいてなんですが、初期化は失敗しました。
なんでも、「PCを初期状態に戻すときに問題が発生しました。変更は行われませんでした」とのこと。
まあ、いろいろと知見が得られたのでいいとしましょう。
あとは、暇を見つけてここの対処法8(クリーンインストール)を実施してみます。
これで、ほんのちょっぴりとQOLが上がりました。
2021/09/23
ここを参考に、クリーンインストールしました。
無事Windows10が動く様になりました。
そういえば、11出るんだよなぁ…
MSBuildの使い方
Windowsには、標準でC#コンパイラ(csc.exe)があります。 なので、VisualStudio(VS)がなくても、C#によるコーディングができます。
ただ、リンクとかめんどくさく、できればもっと簡単にコーディングできるようにしたいです。
MSBuild.exeというも、Windows標準に入ってます。 これを使えばVSなしでビルドができます。
今回は、この使い方をまとめて行きたいと思います。
最終目標は、MSBuildを使ってDebugシンボルを使ったビルド切り替えができるところまでやります。
イメージとしては、MSBuildはC#特化のMakeみたいな感じです。
詳しくはGitHubにサンプルおいておいたので、そちらを確認ください。
TL;DR
- C:\Windows\Microsoft.NET\Framework\v4.0.30319にPathを通す(MSBuild.exe)
- 開発ディレクトリにHoge.csprojファイルを作成する
- 開発ディレクトリでMSBuild.exeを実行する
MSBuildとは
Microsoft Build Engine は、アプリケーションをビルドするためのプラットフォームです。 MSBuild とも呼ばれるこのエンジンには、ビルド プラットフォームでソフトウェアを処理およびビルドする方法を制御する、プロジェクト ファイル用の XML スキーマが用意されています。 Visual Studio は MSBuild を使用しますが、MSBuild は Visual Studio に依存しません。 プロジェクト ファイルまたはソリューション ファイルに対して msbuild.exe を実行すると、Visual Studio がインストールされていない環境で、製品の統合とビルドを実行できます。
https://docs.microsoft.com/ja-jp/visualstudio/msbuild/msbuild?view=vs-2017を読んでおけばおk。
VSなしでアプリケーションをビルドするプラットフォームです。
ソースを準備する
Hello, Worldを表示する簡単なプログラム。
DEBUGシンボルを使って、ビルドを切り替えてます。
using System; namespace Program1 { class Program { static void Main(string[] args) { #if DEBUG Console.WriteLine("Hello, DEBUG!"); #else Console.WriteLine("Hello, world!"); #endif } } }
MSBuildにPathを通す。
パスは以下。
C:\Windows\Microsoft.NET\Framework\v4.0.30319
Frameworkとv4.0.30319はお好みに合わせて変更します。
ちなみに、上記Pathにcsc.exe(C#コンパイラ)もいます。
hoge.csprojを作成する。
hoge.csprojファイルでビルドの詳細を設定します。
VSで、プロジェクト > プロパティ で設定できる項目は、大体設定できる印象。
注意点は以下。
ToolVersionは4.0
ToolVersionを4.0と書かないと、WinForm系のビルドができなかった気がする。
<Project ToolsVersion="4.0" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
C:\Windows\Microsoft.NET\Framework\v4.0.30319\Microsoft.CSharp.targetsは安牌
上記ファイルを読み込んでおけば、コンパイラの設定をしなくてもDebugシンボルが使えるようになる。
使nい場合は、csprojファイル内に<Import Project="$(MSBuildToolsPath)\Microsoft.CSharp.targets" />と書きます。
安牌を使わない場合
PropertyGroupで、Debug/Release時の設定をそれぞれを行います。
その後、Target要素の中に、CSC要素を追加します。
CSC要素の属性値DefineConstantsでDebug/Releaseを指定します。
<PropertyGroup>
<AssemblyName>helloworld</AssemblyName>
</PropertyGroup>
<!-- Releas以外はすべてDebugとする -->
<PropertyGroup>
<OutputPath>bin\Debug\</OutputPath>
<DebugSymbols>true</DebugSymbols>
<DefineConstants>DEBUG;TRACE</DefineConstants>
</PropertyGroup>
<PropertyGroup Condition=" '$(Configuration)' == 'Release'">
<OutputPath>bin\Release\</OutputPath>
<DefineConstants>TRACE</DefineConstants>
</PropertyGroup>
<ItemGroup>
<Compile Include="*.cs" />
</ItemGroup>
<Target Name="Build" Inputs="@(Compile)" Outputs="$(OutputPath)$(AssemblyName).exe" >
<Message text="DefineConstants: $(DefineConstants)" />
<Message text="$(MSBuildToolsPath)\Microsoft.CSharp.targets" />
<MakeDir Directories="$(OutputPath)" Condition="!Exists('$(OutputPath)')" />
<Message text="Create: $(OutputPath)$(AssemblyName).exe" />
<Csc
Sources="@(Compile)"
OutputAssembly="$(OutputPath)$(AssemblyName).exe"
DefineConstants="$(DefineConstants)"
/>
</Target>
ビルドする
-tがターゲット指定、-pがプロパティ指定をする、それぞれのオプションです。
上記のようにcsprojファイルが記述されている前提ですが、Debugビルドをする場合は、-pオプションで指定します。
$ msbuild -t:build -p:Configuration=Debug
終わりに
プロジェクトによっては、自由にアプリケーションや実行環境を導入できない場合があります。 (というか、それがだいたいです)
Windowsだったら、それでもC#が使えるので、代替品を自作することができます。
(Linuxならもっと自由ですが)
C#で自作ツールを作成し、貧弱なWindows環境でもちょびっとだけ業務効率を上げることが出そうです。
これで、QOLがちょびっとだけ上がった。